





June 2, 2026
By Omar Alsaied
General Manager of Business Development, Saudi Arabia
Ciena’s Omar Alsaied examines why the GCC’s AI ambitions are shifting the network from supporting infrastructure to strategic architecture, as scale across designs help distributed GPU sites operate as one coherent AI training platform.
The GCC’s AI network question is changing
If you are building AI infrastructure in the Gulf Cooperation Council (GCC), the design question has changed. It is no longer only about how many GPUs can fit into one hall. It is how effectively multiple halls, buildings, campuses, and metro sites can be connected so they behave like a single integrated training system.
That is the shift behind scale across architectures. Ciena describes scale across as the ability to train one AI model across GPUs in different campuses or regions. The idea is gaining relevance because AI clusters are expanding from tens of thousands of GPUs toward much larger environments, while Ciena estimates that more than 300 new AI data centers will be operationalized worldwide in 2025, rising to nearly 600 new data centers added in 2030.
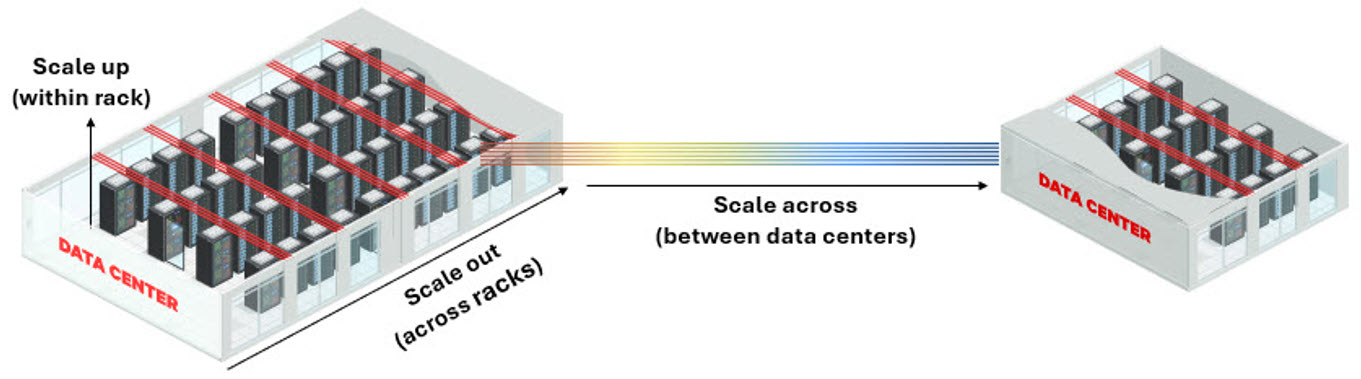
Figure 1: Scale up, scale out, and scale across are the three design dimensions of AI infrastructure
Why the GCC is becoming relevant for distributed AI
The GCC is already home to growing—and robustly connected—cloud infrastructure. AWS has its cloud regions designed around multiple, physically separate availability zones connected by redundant, low-latency networks, and has announced a new cloud region in Saudi Arabia. Google Cloud has also opened its Doha cloud region in Qatar, adding another regional cloud node to the Gulf’s digital infrastructure base.
The AI layer is now scaling on top of that cloud foundation. In Saudi Arabia, HUMAIN and NVIDIA announced plans for AI factories with projected capacity of up to 500 megawatts over five years, with the first phase built around an 18,000 NVIDIA GB300 Grace Blackwell AI supercomputer. AWS and HUMAIN also announced plans to invest more than $5 billion in an AI Zone in the Kingdom, separate from the AWS region already under construction.
The UAE is moving in the same direction. G42 announced a 5GW UAE-US AI Campus. OpenAI then announced Stargate UAE, including a 1GW cluster in Abu Dhabi with 200MW expected to go live in 2026. Microsoft and G42 separately announced a 200MW increase in data center capacity in the UAE, while the Oracle Cloud Abu Dhabi Region is set to host the Middle East’s first OCI supercluster powered by more than 4,000 NVIDIA Blackwell GPUs.
The architectural direction is becoming harder to ignore. AI capacity in the GCC is likely to expand across campuses, power domains, cloud zones, and metro footprints rather than concentrate indefinitely inside a single facility. That does not necessarily mean operators will immediately run frontier multi-site training across those environments. Many AI deployments today still operate as isolated clusters.
However, as AI infrastructure scales, physical constraints such as power availability, phased campus development, resiliency requirements, and sovereign AI considerations may increasingly push operators toward architectures where compute capacity is distributed across multiple locations while still needing to function cohesively. For hyperscalers, neoscalers, and regional service providers, the challenge is not simply site growth. It is cluster coherence across distance.
Why the Gulf may become relevant for distributed AI
There are also practical reasons why the Gulf is becoming relevant for scale across networks.
Power and site planning are becoming central to AI infrastructure strategy. Access to power, cooling, land, and deployment timelines increasingly shape where AI capacity can realistically be built. As AI clusters grow toward larger power and cooling envelopes, scaling entirely within a single facility may become operationally and economically difficult in some environments, particularly when grid access, resiliency goals, and sovereign requirements differ across locations. The partnership landscape is also moving quickly. center3 and HUMAIN announced a joint venture to develop AI data centers in Saudi Arabia with up to 1GW of AI workload capacity, starting with an initial capacity of up to 250MW. HUMAIN has also secured financing from the National Infrastructure Fund to support up to 250MW of AI data center capacity. These are not isolated announcements. They point to a market where AI capacity may increasingly be deployed in phases, across multiple sites, and around national infrastructure priorities.
Sovereign and language-led AI demand adds another layer. Saudi Arabia is investing in Arabic-first AI, while regional models such as Jais in the UAE and Fanar in Qatar show how Gulf AI infrastructure is being shaped by local language, culture, and jurisdictional requirements. Those requirements may further increase the importance of local and regional connectivity.
From multi-site cloud to multi-site training
To be clear, most AI training today still happens within individual clusters rather than across geographically distributed sites. Cloud platforms have long been designed to operate across multiple data centers for resilience and availability. Distributed AI training demands more. Some hyperscalers and AI infrastructure operators are beginning to explore how geographically separated GPU clusters could behave more like one logical training environment as models, power requirements, and infrastructure scale continue to grow.
That makes the inter-data-center network part of the AI system. Every delay variation, congestion event, and packet loss event can affect training efficiency. Once training extends beyond a campus, traditional interconnect approaches are no longer enough. The optical layer must support ultra-high capacity, strong reliability, and consistently low and predictable latency.
The timing and extent of that transition remain uncertain and will vary by operator, workload, and geography. But if AI infrastructure growth increasingly outpaces what can practically be deployed inside a single site, inter-data-center networking may evolve from a resilience layer into part of the AI training fabric itself.
Why scale across is different from conventional DCI
Conventional data center interconnect has often been optimized for efficient transport between sites. Scale across AI is different. The goal is not simply to move traffic between data centers. It is to make two or more data centers behave like one cluster. Multi-site training depends on the inter-data-center network acting as a deterministic extension of the intra-data-center fabric.
That distinction matters in the GCC. In many deployments, power availability, sovereign AI requirements, and resiliency goals will determine where compute lands first. The network then has to span the distance between those locations without introducing enough loss or latency variation to reduce GPU efficiency. Geography becomes a strategic advantage only if the selected sites can make the network behave predictably.
This is also why DCI should not be treated as a narrow metro-only use case. Ciena sees today’s DCI landscape as extending from campus, metro, scale across, and submarine connectivity, while also evolving to support emerging scale across AI architectures with very different performance and operational requirements. For the GCC, that matters because AI infrastructure may need to connect campuses inside one metro, sites across a national footprint, and eventually regional routes across borders.
Two scale across designs for distributed AI infrastructure
The first pattern is near scale across. This is the architecture used when GPU clusters are spread across a campus, metro area, or regional footprint, and the goal is the simplest possible design. The priority is to maximize reach while avoiding intermediate amplifier sites wherever possible. Ciena’s scale across work points to C- and L-band 800 Gb/s coherent pluggable connectivity, Raman-assisted reach extension, and optical protection as important tools for these deployments. In some environments, operators may need tens of Pb/s between sites and full capacity on day one, not a slow ramp of partially lit fiber.
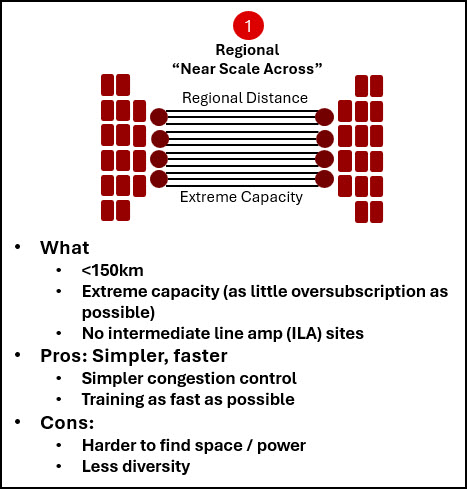
Figure 2: Near scale across uses simple regional designs to extend one AI training environment across campuses and metro sites
The second pattern is far scale across. This is what happens when AI infrastructure spans broader regional distances. At that point, intermediate line amplifier sites become unavoidable. The problem shifts from terminal simplicity to physical route densification. More fiber pairs, more efficient amplification, and much higher photonic density are needed so that space, power, and operations do not grow disproportionately as the route grows.
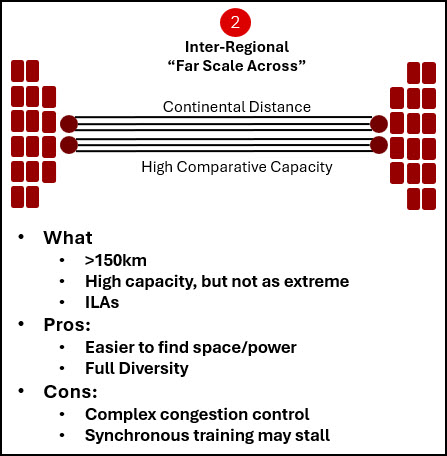
Figure 3: Far scale across extends one AI training environment across inter-regional or longer-distance routes
For large, multi-region AI connectivity, the physical route becomes part of the architecture. Ciena’s RLS Hyper-Rail configuration is designed to address that challenge by increasing fiber density and improving route scalability for high-capacity AI environments.
What to optimize first
Start with consistent network performance, not just peak bandwidth. Raw throughput matters, but sustained AI training performance depends just as much on keeping latency and congestion behavior consistent under load. If the network cannot keep latency predictable under load, distributed training efficiency can fall before traditional bandwidth or utilization metrics show an obvious issue . Scale across requires coordination between packet-layer congestion management and the optical layer underneath.
Next, plan for operational consistency across multi-vendor AI infrastructure. Heavy Reading’s 2025 survey found that operators prioritize multi-vendor interoperability, longer reach and performance, and low power for coherent pluggables. It also highlights the operational challenge of consistent performance and operational practices across vendors. For hyperscalers and neoscalers, that is a useful reminder: scale across success depends as much on the operating model as on the transceiver itself.
Finally, build operational insight into the photonic layer from the start. Ciena’s 6500 RLS emphasizes automation for wavelength turn-up, stable optical performance as capacity grows, and embedded instrumentation for characterization and monitoring. In AI environments, that discipline is not optional. It is how operators shorten turn-up time and reduce the GPU time lost to network uncertainty.

Figure 4: Scale across requires coordination between packet and optical layers to connect GPU clusters across sites
The GCC is not simply adding AI capacity; it is increasingly creating the conditions for distributed AI architectures at regional scale. It is assembling the conditions for distributed AI at national and regional scale. That changes the role of the network between data centers. It can no longer be treated as a secondary transport layer. It may increasingly need to be designed as part of the training architecture itself.
For hyperscalers, neoscalers, and regional operators, the opportunity may increasingly lie in placing compute where power, policy, resiliency, and growth plans align, then using coherent optics and programmable photonics to help those sites operate with greater coordination and efficiency. That is the underlying promise behind scale across architectures, and one reason the GCC is becoming an important region to watch as distributed AI infrastructure evolves.